NOTES:
|
Back to top: Multinodal Index
Introduction
The “multinodal indices” (program MNI) are tools to navigate the underlying bibliographical data of this website. They are built by extracting keywords from the summaries present in the bibliography. Keywords are ranked by co-occurrence in other summaries that contain the same keyword, and by strength as measured by the number of occurrences in a given reference. Then they are plotted as a force-directed graph.
This visualization permits the user to explore connections that are implicit in the data, but not explicitly coded in the form of notes or hyperlinks. The keyword search function navigates the lateral connections that exist when the same keywords are used by a group of authors.
The author search function intially returns the “keyword space” of a given author, and links to other authors who use the same keyword in their works. Most elements are clickable, returning more information or direct links to the relevant bibliographic entry.
The author comparison visualization overlays two authors over the entire “keyword space” that represents all authors contained in the bibliography. It can give an indication of how completely an author covers the entire space, and how closely two authors’ interests intersect. It is important to note that this representation is based only on the bibliographical material present on this site: therefore, it does not accurately represent the actual content of the author’s body of work, but only the subset present on this site, filtered through the lens of the scholar who summarized the work(s) in the bibliography. When the comparative tool indicates an interesting intersection or non-intersection of two authors, follow the bibliographical links for the context in which to interpret the results.
Please note that these indices can take a few seconds to load, depending on internet connection speed.
The visualization software was developed in collaboration with Blevmore Labs.
Back to top: Multinodal Index
Background
When we designed the linear indices, we noticed that the keywords chosen by the author of a summary barely cover the semantic space of the summaries themselves. We wondered if we could find a better way to parse the data contained in these files, and create more useful indices. At the same time, we wondered if we could find a way to represent the connections between entries, as well as their granular data. A linear index represents information atomized into constituent parts; another useful tool would be a representation of the similarities between entries.
When the eye scans a linear index, it can quickly sort through the words of interest and those that are not related to the questions that currently interest the reader. But the list of keywords is “flat”, containing little information about the relations between the words. It is true that the amount of references carried by a keyword give some indication of its relative importance in the present context, but a second layer of information is entirely hidden. Keywords form clusters: some are closely related, and define a domain of information. Others are simultaneously present in the overall website, but never co-occur in an article or bibliographical summary. This fact led to the development of what we call the “multinodal index”. By seeing the connections, and the lack of connections, between keywords, it would become possible to navigate the site with greater depth and insight.
Back to top: Multinodal Index
Keyword Extraction
Given the large amount of text that makes up our bibliography, it seemed imperative to develop an automated method for extracting keywords from the text of the DABI file itself, as a supplement to the keywords deemed most important by the summary authors. Two distinct indices could then be generated, one reflecting each scholar’s judgment about what is most important, and another that contained a pathway to every significant word contained in the entire corpus on the website.
Extracting keywords from plain text is not an unusual task, and many methods exist to do it. One method consists in breaking a text into words at every “whitespace” character, and throwing away “stop words” like articles and prepositions. A further step might be to make all words lowercase, so as to eliminate one of the errors mentioned above, where “Asherah” and “asherah” appear as distinct keywords. However, this procedure is unable to account for plural and singular, for proper names, and for words like “through” that are complex enough to often escape filtering for stop words, but which are not real keywords. One might also prefer to filter adjectives and adverbs from a keyword list, and retain only nouns and verbs—or even just nouns. To solve these problems and build a system to aid in navigating our indices, we used an open-source software package called SpaCy.
The essential logic of SpaCy is easy to implement. A few lines of code in Python suffice to unlock the functionality:
nlp = spacy.load("en_core_web_md")
doc = nlp(sentence)
for t in doc:
if len(t)<3: #get rid of short words
continue
if t.pos_ == 'NUM' or t.pos_ == 'AUX' or t.pos_ == 'ADP' or t.pos_ == 'SYM':
# get rid of numbers, auxiliary verbs, prepositions, symbols
continue
if t.pos_ == "PROPN": #put proper names in the list with capital letter
topic_list.append(t.lemma_)
continue
if t.pos_ != "NOUN": #keep only nouns
continue
topicToAdd = t.lemma_
topicToAdd = topicToAdd.lower() #make everything except proper names lowercase
topic_list.append(topicToAdd) #append the lemma of each word to the list
First, the English language medium sized model is loaded as the nlp object, which is a good compromise between speed and accuracy. Then, each sentence of the document (previously parsed) is passed through the nlp model and assigned to the “doc” variable as a list of words with part-of-speech attributes, word vectors, and other syntactical information. All of this is hidden below the surface, which makes SpaCy exceptionally easy and clean to use.
It is then simple to iterate through each word in the sentence: for each word (referred to as “t” in the above code), the program carries out a series of tests. First, if the word is only one or two characters long, the program skips to the next word without further action (“continue” means to skip over all subsequent instructions, and move to the next word in the sentence). If the word’s POS (part of speech) is Number, Auxiliary verb, Preposition, or Symbol, it is skipped. Proper names are included in the list of keywords as lemmas, maintaining the capitalization of the first letter. Then all words that are not nouns are skipped, which leaves only nouns to be included in the list of keywords, since the last few lines of the loop are only reached in this case. They are first lemmatized, so that prefixes and suffixes do not distract the program into considering identical lemmas as distinct keywords. Then they are converted into lowercase and added to the “topic_list”, which is the list of keywords.
It may be noted that the logic of this simple program is redundant: could it not distinguish nouns from all the other parts of speech without the first line? In testing, we found that it was more error prone to place the major discrimination element entirely on the shoulders of one command, and that by first eliminating some parts of speech it could more accurately identify the nouns. On its own, SpaCy is only 90% accurate in its labelling of the part of speech of each word. We reasoned that it was more important to avoid spurious keywords than to ensure that all keywords were represented, since the goal of this index is to help a human user find useful information. Other use cases might choose a different priority.
The rest of the program manages the connections between information in such a way as to generate a table such as this (the actual table generated contains hundreds of rows and many keywords per row; this table is truncated for brevity and clarity):
|
filename |
author |
year |
keywords |
|
|---|---|---|---|---|
|
0 |
Nissinen2019Divination |
Nissinen, Martti |
2019 |
[divination, essay, Eastern, Prophecy, prophec...] |
|
1 |
Cohen2018MoralityInAntiquity |
Cohen, Yoram |
2018 |
[morality, Antiquity, tradition, proverb, comp...] |
|
2 |
Scheil1913Memoires |
Scheil, Jean Vincent |
1913 |
[Memoires, mission, Susiane, Vol, dream, Appen...] |
|
3 |
Rubio1999Substratum |
Rubio, Gonzalo |
1999 |
[Alleged, Substratum, substratum, problem, Sum...] |
|
4 |
CDLI |
None |
2021 |
[Cuneiform, Digital, Library, Initiative, cune...] |
Some errors are clear in these few lines: “Alleged” should not have been included, and “Substratum” and “substratum” are duplicates that were not properly united, probably because the model incorrectly labeled “Substratum” as a proper name. Also, the French language words in Scheil’s text confuse the system because it only uses one language model at a time, and cannot distinguish French words from the English in the surrounding text, which means the French text is incorrectly labeled. Still, it is an acceptable rendering of the keywords of each bibliographical entry, not messier or more redundant than the keyword list generated by our research team.
Back to top: Multinodal Index
Generating the Multinodal Index
Calculating the strength of connection between each node representing a single work in the bibliography is a question of how to model the data, and is a crucial interpretative step. We consider two nodes (or bibliography entries) as “connected” if they share at least five keywords, and not connected if they share less than five. The strength of the connection can also be represented on a sliding scale based on the number of shared keywords. Similarly, the size of each node is determined by the number of keywords in it. More detailed bibliographical entries, with more keywords, are represented as larger nodes.
Once this calculation is performed, it is straightforward to plot the nodes and their connections as a force-directed graph using open source Python libraries, widely used today in data science. This representation offers a simple and intuitive map of the density, or lack thereof, of groups of nodes. It shows which bibliographical entries cover a similar “semantic space”, and which are isolated from the rest.
Back to top: Multinodal Index
The Force-Directed Graph
Force-directed representations are based on the physics of charged particles connected by springs. Each particle has the same charge, and repels all the others; each spring attracts the two particles it connects. Thus, in our representation, each node has a “charge” that is proportional to the number of keywords it contains. Left to themselves, each particle will repel all the others and fill the space with a maximum distance between all particles. But many of the nodes are connected with “springs” that pull them together, with an attractive force in proportion to the number of keywords they share. This means that the space will be filled with clusters of related nodes, and less-related clusters or single nodes will be pushed away, where they can easily be identified.
A simple force-directed graph is below:
From this representation, one can immediately see that the two light orange nodes on the left are unconnected to the rest of the graph. It might be relevant to understand what they are, and why they are eccentric with respect to the rest. Similarly, one can see that a small number of large nodes act as “gatekeepers” holding the network together, in a sense controlling “traffic” between less well-connected nodes. In this representation, this fact might mean that they are among the more important works in the bibliography, since they have been described at greater length. We applied this method to the table of bibliographical entries and keyword lists on our website about Mesopotamian religion, and filtered the network to represent only those works that contain a given keyword. Below is an example of the keyword representation of all works containing the word “ritual”:
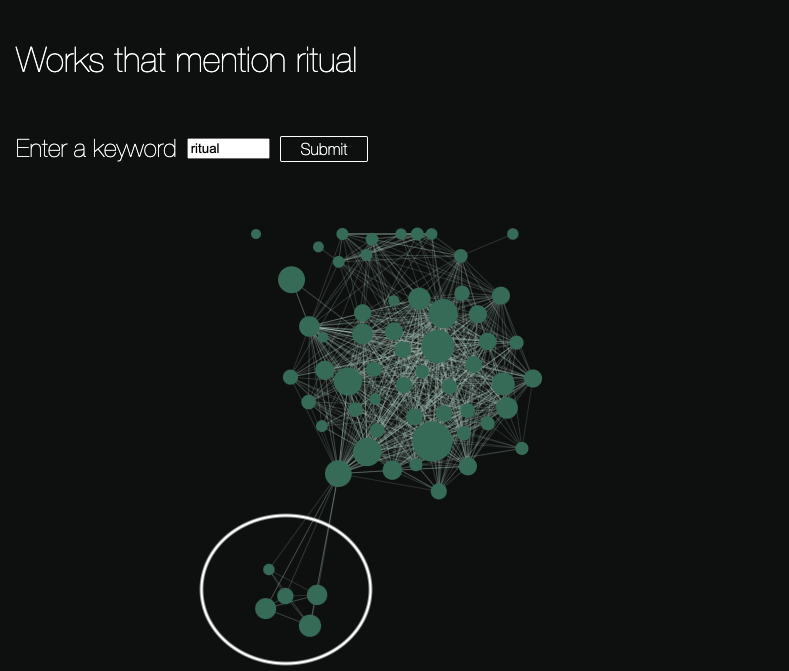
In this case, the topology of the graph contains a group of connected works to the bottom left which are special: they form a connected group that has its own identity, and is connected to the rest of the graph through only one node. Examining those five nodes, we discover that they are all written by Catholic authors such as Pope John Paul II: while they do contain the word “ritual”, and share some number of keywords with one of the major works in the central cluster, they also constitute an independent group of similar works that are not well connected to the main body of texts dealing with Mesopotamian religion, as we might expect, given their authors.
The force-directed graph representation allows an intuitive way to navigate the bibliography that contains more information than a simple keyword search could provide. Let us remember that in a keyword search, or in the linear index already discussed, works are not distinguishable based on the “semantic space” they cover. All works that contain a given keyword are on the same level, so to speak. By using a force-directed graph representation, it is possible to give the user a bit more information about which works are most relevant, important, and well-connected to the rest of the present corpus.
The same technique can be used to represent a single author across all their works contained in the bibliography. For example, Thorkild Jacobsen’s contributions are mapped in this graph:

In this representation, nodes correspond to single keywords, and they are connected to other keywords that co-occur in the same text. The largest, most central node is “Mesopotamia”, and we can see a complex web of connections to other words starting from that point. While this map is already too complex to be intuitively useful, it can form the basis for mathematical analysis and comparison.
The third multinodal index is a mapping of keywords across the entire bibliography, in such a way as to permit direct comparison between two authors. The author comparison visualization1 overlays two authors on the entire “keyword space” that represents all authors contained in the bibliography. It can give an indication of how completely an author covers the entire space, and how closely two authors’ interests intersect. It is important to note that this representation is based only on the bibliographical material present on this site: therefore, it does not accurately represent the actual content of the author’s body of work, but only the subset present on this site, filtered through the lens of the scholar who summarized the work(s) in the bibliography. When the comparative tool indicates an interesting intersection or non-intersection of two authors, one can follow the bibliographical links for the context in which to interpret the results.
How do two authors measure up? How well do they cover the “keyword space” of the entire corpus present on our site? One way to compare across a large space with thousands of interconnected keywords is to show only the nodes, but place them on the two-dimensional screen in a way that mirrors to some extent their underlying structure1. This means that closely placed nodes share some connection, in this case co-occurrence with their neighbors. And by simply highlighting the nodes belonging to two authors in two different colors, the two can be compared. The comparison of Jacobsen and Cohen is below, with Jacobsen in blue, Cohen in yellow, and shared keywords in green:
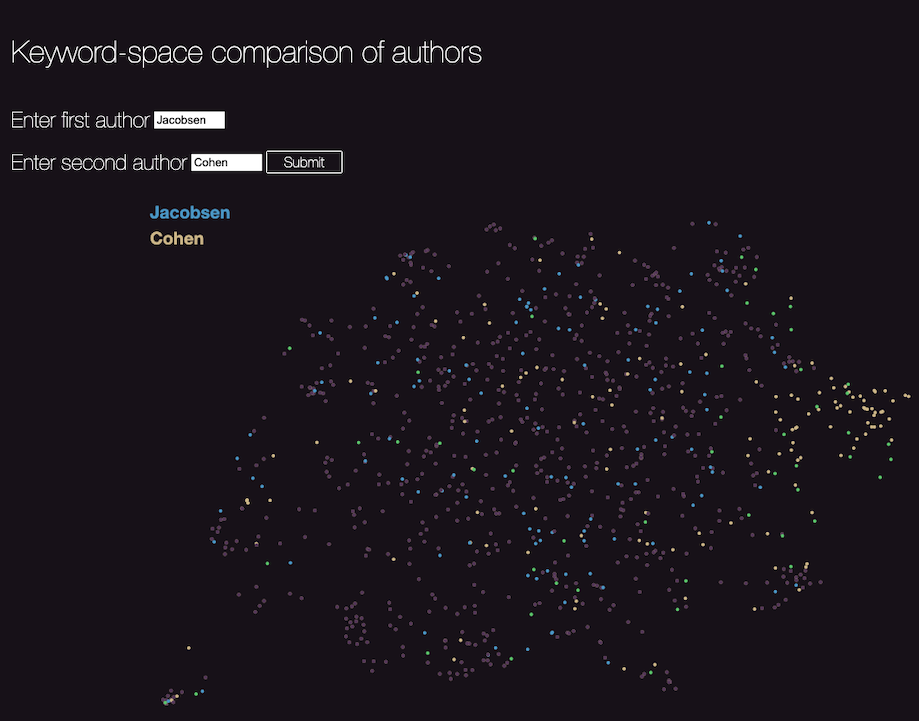
Cohen’s contribution clusters in the right extremity of the field; there is significant overlap between the two authors (the green nodes are well-dispersed); and both authors cover the field fairly completely. It is difficult to represent the usefulness of this tool on a static page, and readers are encouraged to try it for themselves here.
These visualizations permit the user to explore connections that are implicit in the data, but not explicitly coded in the form of notes or hyperlinks. The keyword search function navigates the lateral connections that exist when the same keywords are used by a group of authors. The author search function initially returns the “keyword space” of a given author, and links to other authors who use the same keyword in their works. And the author comparison tool aids direct comparison of two authors across the “keyword space”. Most elements are clickable, returning more information or direct links to the relevant bibliographic entry.
Back to top: Multinodal Index
Interpreting the Multinodal Index
The two force-directed graphs should be interpreted as a graphical representation of the strength of connection between elements, as described above. The third image, the projection of the entire “keyword space”, requires further explanation. It reproduces a map of the keywords present in the bibliography, located on a two-dimensional surface in such a way as to retain some of the high-dimensional structure of the keywords.
How precisely to represent high-dimensional data on a two-dimensional screen is the object of intense research in data science. One popular method, known as t-SNE, was developed by van der Maaten and Hinton in 2008. See distill.pub for an introduction to the method, with interactive visualizations that help see how powerful the procedure is, and how easy it is to misinterpret its results.
Our multinodal index uses a UMAP projection of the keywords. UMAP is a recently developed procedure (2018) based on the older t-SNE method. An introduction, with interactive visualizations, written by Google’s Andy Coenen and Adam Pearce can be found at pair-code.github.io. The three-dimensional image of a mammoth mapped to a two-dimensional representation is a particularly helpful example: it offers an easy way to intuit the nuances of the problem of projecting high-dimensional structures to two or three dimensions. It also offers a direct comparison of t-SNE vs. UMAP on the same dataset. By playing with the parameters on this site, it is easy to perceive how a UMAP projection of data can retain some of the global structure while being difficult or impossible to interpret on its own. The meaning of the structure therefore is often limited to showing data points that are close in their native dimension.
The plot available on our site has this same limitation. It is not possible to say what precisely the location of a given keyword means; at most, we can say that keywords that are represented close in the multinodal index are also close in their native dimension, which is the bibliographical database. Further research will optimize the parameters used, in order to bring internal clustering into focus, which might lead to interesting conclusions regarding the way different authors treat macroscopic topics.
Back to top: Multinodal Index