Back to top: MNI: Detailed Explanation
Interpreting the Multinodal Index
The “4Banks” cluster of websites aims to create a form of writing that is multilinear and multiplanar (see full discussion here. In the context of this aim, the Multinodal Index (MNI) visualizations were developed in order to permit the reader of the site to explore connections that are implicit in the data, but are not explicitly coded in the form of notes or hyperlinks. The MNI is thus a layer of algorithmic multiplanarity that supplements the interconnected layers that were explicitly written by the authors of the site. Interpreting this layer requires some understanding of network analysis: in the “quickstart” a few intuitive concepts were introduced. In this page, we provide more details for the interested reader.
Back to top: MNI: Detailed Explanation
Keyword search
The keyword search function navigates the lateral connections that exist when the same keywords are used by a group of authors. The force-directed graph of keywords can be interpreted as a visual representation of the strength of connection between the works contained in the bibliography. Each node represents a work in the bibliography that contains the search term. The size of the node represents the number of keywords contained in that work. This implies that larger nodes have more detailed entries in the bibliography. Connections between nodes are formed when two works share at least five keywords. The connection strength (=number of shared connections) is graphically represented by the color of the line connecting two nodes. The brighter the line, the stronger the connection. In the “quickstart”, we pointed out situations in which a search term returns networks with an interesting topology, indicating groups of works that address a given topic from a few different points of view.
Back to top: MNI: Detailed Explanation
Author search
The author search function initially returns the “keyword space” of a given author, representing it as a network of nodes (keywords) connected to other keywords that co-occur in the same text. On the side of the image, there is a list of links to other authors who use the same keywords in their works. (In the case of a display which is too narrow, this list of connected authors will be visualized below the network representation).
This visualization can be interpreted as a network of keywords found in a single author, across all their works contained in the bibliography. For example, Thorkild Jacobsen’s contributions are mapped in this graph:

The largest, most central node is “Mesopotamia”, and we can see a complex web of connections to other words starting from that point. This representation can be interpreted as a semantic map that not only lists the main keywords in the bibliography of that author, but also provides a way to access the relative importance of those terms, on the basis of the size and centrality of the words represented.
It can also be used as a way for the reader to notice peripheral terms that are not well connected to the central cluster, and thus represent issues that the author does not deal with closely. As usual, a caveat applies: since these representations are automatically generated from the material present in the site bibliography, they do not necessarily represent the authors, so much as the website research team who have summarized their works.
Back to top: MNI: Detailed Explanation
Author comparison
The author comparison tool aids direct comparison of two authors across the “keyword space” of the entire website. The author comparison visualization first establishes a map of all the keywords found in the entire corpus of the website. These words are located in two-dimensional space by means of the UMAP algorithm (see below). Then, the visualization allows the researcher to overlay two authors on the entire “keyword space”, to see how they compare with each other and how they each cover the overall space.
At the current state of development, this visualization is most useful as a way to compare two authors with respect to their coverage of the overall list of topics found in the site. For example, the reader may notice that Jacobsen and Cohen are both frequently quoted in the articles on the site, and may wish to compare how much these two authors contribute to the overall contents. Perhaps the reader is also interested to see how much these two authors overlap in their interests, and how widely distributed those interests are. The relevant visualization is:
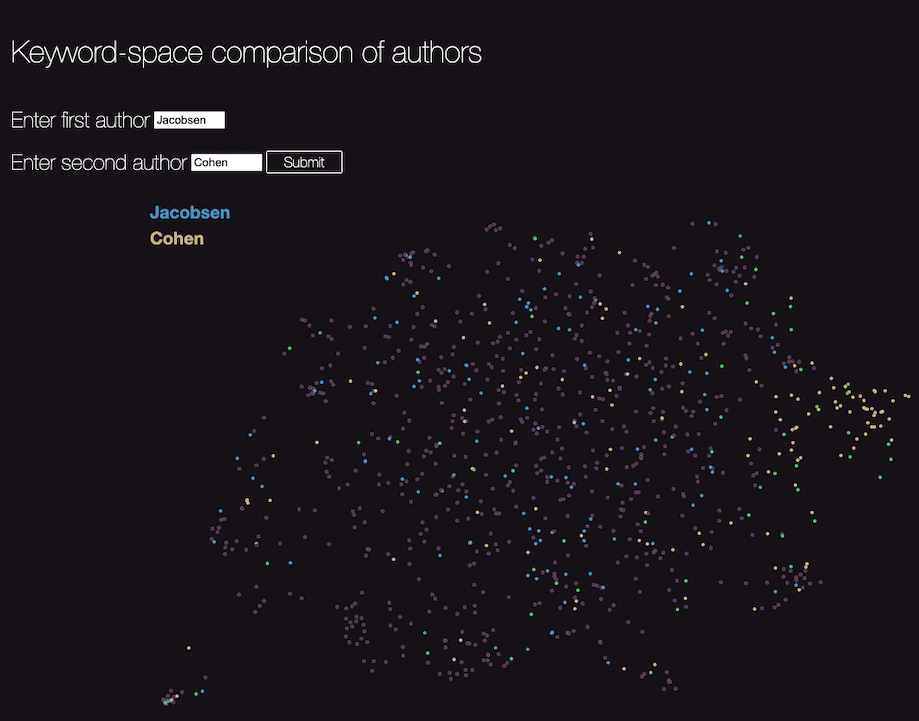
In this image, the yellow color indicates the keywords present in Cohen’s work, the blue color indicates the keywords in Jacobsen’s work, and green keywords are those that are shared between the two authors. Purple dots indicate other keywords that are not found in either author. Because of the spatial distribution of words, we may be interested not only in the overall distributions, but also by the fact that Cohen’s contributions cluster in the right-hand part of the space. See below, (UMAP Representation) for more information about the meaning of the spatial distribution.
We thus have four sets visible simultaneously: the entire “universe” of keywords present in the site (purple); those that are shared by the two authors (green); and the two sets that are exclusive to one or the other author (blue and yellow). Since the elements are clickable, returning more information or direct links to the relevant bibliographic entry, the reader can use this map as a way to navigate the bibliography by topic instead of by author name. When the comparative tool indicates an interesting intersection or non-intersection of two authors, one can follow the bibliographical links for the context in which to interpret the results.
Back to top: MNI: Detailed Explanation
Further interpretation
Sometimes, these visualizations are too complex to be intuitively understandable. This is particularly true when there are so many keywords, or so many connections between the works of a prolific author, that the cluster appears messy and impenetrable to the human eye. For instance, a search for the term “god” produces the following image:
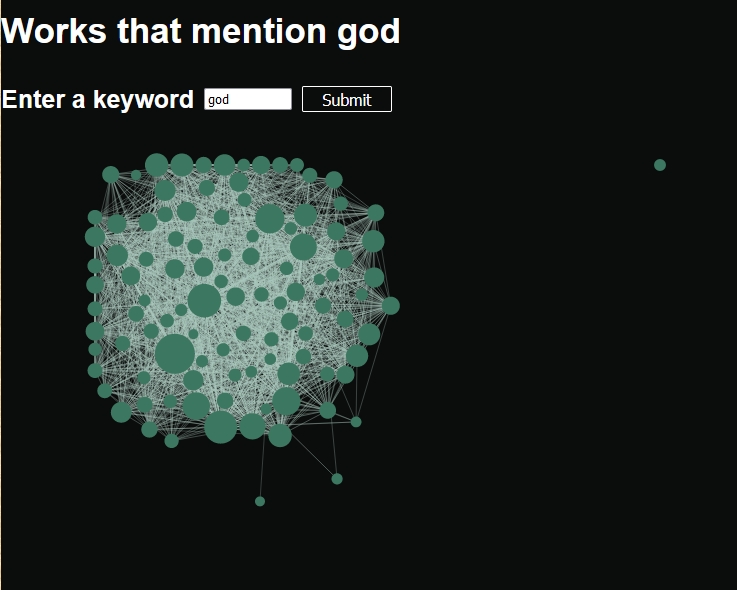
One feature that can be intuited in this case is the existence of an outlier displayed here at the top right, which contains the search term but is otherwise unconnected to the rest of the cluster. We can also identify several large nodes containing the search term, and infer that they are probably important works in the bibliography, because they contain many keywords. More advanced analysis is also possible, although our website does not yet contain the tools to perform it directly. The “translation” of text information into visualizations and mathematical structures such as networks and UMAP dimensional reduction offer additional tools to the historian. Using network analysis, topic clusters can be identified; central nodes (for instance, seminal works in the field) can be located and interpreted as “gatekeepers” that determine the flow of information in the network; and more complex topological features such as cavities can also be identified and interpreted. Research in this area is ongoing and we hope that more advanced network analysis techniques will soon become useful for the study of ancient history.
We include these visualizations even when they cannot be directly interpreted in order to indicate a possible direction for further research and development. It is our opinion that as digital writing develops the capacity to explicitly render multiplanar discourses as well as the linear discourse we have used for the last six millennia, humans will need algorithmic tools to navigate the complexity of such discourse. Our multinodal indices are a first exploration of one such tool. They are a first attempt at paying attention to connections as well as to fragments within an index, not yet a mature tool.
Back to top: MNI: Detailed Explanation
Linear vs. Multinodal Indices
The linear indices are created on the basis of keywords which were manually chosen by the authors of the website. In this case, a small number of keywords are chosen to represent the “semantic space” of a given bibliography entry. While preparing the site, we noticed that in some cases the keywords chosen give only a partial indication of the richness and variety of topics mentioned in the bibliography summaries themselves. We wondered if we could find another way to parse the data contained in these files, and create more complete indices. At the same time, we wondered if we could find a way to represent the connections between entries, as well as their granular data. A linear index represents information atomized into constituent parts; it could be useful to also see a representation of the similarities between entries.
When the eye scans a linear index, it can quickly sort through the words of interest and those that are not related to the questions that currently interest the reader. But the list of keywords is “flat”, containing little information about the relations between the words. It is true that the amount of references carried by a keyword give some indication of its relative importance in the present context, but a second layer of information is entirely hidden. Keywords form clusters: some are closely related, and define a domain of information. Others are simultaneously present in the overall website, but never co-occur in an article or bibliographical summary. This observation led to the development of the “multinodal index”. By seeing the connections, and the lack of connections, between keywords, we hoped it would become possible to navigate the site with greater depth and insight.
Back to top: MNI: Detailed Explanation
Producing the MNI
The multinodal indices were created by automatically extracting keywords from the summaries present in the bibliography. Keywords are ranked by co-occurrence in other summaries that contain the same keyword, and by strength as measured by the number of occurrences in a given reference. Then they are plotted as either a force-directed graph or a UMAP projection, depending on which index was chosen.
These visualizations permit the reader to explore connections that are implicit in the data, but not explicitly coded in the form of notes or hyperlinks. The keyword search function navigates the lateral connections that exist where the same keyword is used by a group of authors. The author search function returns the “keyword space” of a given author, and links to other authors who use the same keyword in their works. The author comparison visualization overlays two authors over the “keyword space” that represents all the authors present in the bibliography. When the comparative tool indicates an interesting intersection or non-intersection of two authors, the reader can follow the bibliographical links for the context in which to interpret the results.
It is important to recall that these representations are based only on the bibliographical material present on this site: therefore, they do not necessarily represent the actual content of the author’s body of work, but only the texts present on this site, which is filtered through the lens of the scholar who summarized the work(s) in the bibliography (used to create the multinodal indices) and inserted subject tags (to create the linear indices).
The visualization software was developed in collaboration with Blevmore Labs. Please note that these indices can take a few seconds to load, depending on internet connection speed.
Back to top: MNI: Detailed Explanation
Extracting Keywords
Given the large amount of text that makes up our bibliography, and the varieties of styles and points of view represented by our research team, it seemed useful to develop an automated method for extracting keywords from the text of the DABI files themselves. Automatic extraction should be understood not as a replacement for the manual choice of keywords deemed most important by the summary authors, but as an alternative approach to cataloging bibliography entries. Two distinct indices can thus be generated: one reflecting each scholar’s judgment about what is most important, and another that contains a pathway to each keyword contained in the corpus on the website, whether or not a scholar chose that word manually.
Extracting keywords from plain text is not an unusual task, and many methods exist to do it. One simple method consists in breaking a text into words at every “whitespace” character, and throwing away “stop words” like articles and prepositions. More sophisticated approaches parse the text and identify the lemmas and parts of speech of each word in order to perform linguistic analysis. We chose this latter method for our approach in creating the MNI.
After assigning part-of-speech tags to each word, we chose to retain only nouns for the creation of our multinodal index. This choice is justified by the need to simplify the overall number of keywords and avoid complicating the indices with spurious terms. However, this choice also means that certain important adjectives such as “spiritual” are not present, since only the noun forms “spirituality” and “spirit” are retained by the parsing software. We attempt to distinguish and retain proper nouns. Sometimes, this distinction fails (as in the case of “Asherah” and “asherah”), because the parsing software is not trained on ancient terms that are unusual in modern language models. These shortcomings could be improved by fine-tuning the language model, but we have not yet attempted such a step.
It is worth recalling that other tools present on our site take different approaches. The linear indices are created by manual choice of keywords, and contain terms that can be adjectives, nouns, proper nouns, or other parts of speech. The linear index also contains phrases, like “divine anger” and “humor in cuneiform wisdom texts”, as well as textual references like “Is. 45, 1-17” and words in a variety of ancient languages. These keywords/keyphrases were chosen by our team of scholars and represent a human judgment about the importance of given topics; they also represent the idiosyncrasies of such judgments when made by a team that communicates imperfectly and by single researchers who only imperfectly remember which exact keyphrases they used in the past. For instance, the topical index contains overlapping entries like “god’s attributes”, “god’s symbols”, and “god’s symbols and attributes”.
Furthermore, the overall website search tool is built using Lunr, which operates by “stemming” each word according to an internal dictionary. See here for details. While this approach often returns similar results to the approach used in the creation of the MNI, in some cases it is different. For instance, a global search for ’spirit’ returns only the noun; whereas a search for ’spiritual’ returns also ’spirituality/spiritualities’ and vice versa a search for ’spirituality’ returns ’spiritual’ as well, but not ’spirit’. The same searches performed on the MNI will return only the bibliography entries that contain ‘spirit’ or ‘spirituality’, since only nouns are retained in this index, instead of all words that contain a given stem. This is because stemming is a heuristic approach that produces good, but sometimes linguistically inconsistent results, whereas lemmatization requires more processing power and more complex models, but produces more valid results. See discussion here.
Back to top: MNI: Detailed Explanation
Keyword Extraction Software
In order to create the MNI by automated keyword extraction, we used a software package called SpaCy. The essential logic of SpaCy is easy to implement. A few lines of code in Python suffice to unlock its functionality.
For each word in the text, the program carries out a series of tests. First, if the word is only one or two characters long, the program skips to the next word without further action. If the word’s POS (part of speech) is Number, Auxiliary verb, Preposition, or Symbol, it is skipped. Proper names are included in the list of keywords as lemmas, maintaining the capitalization of the first letter. Then all words that are not nouns are skipped, which leaves only nouns to be included in the list of keywords, since the last few lines of the loop are only reached in this case. They are first lemmatized, so that prefixes and suffixes do not distract the program into considering identical lemmas as distinct keywords. Then they are converted into lowercase and added to the “topic_list”, which is the list of keywords. It may be noted that the logic of this simple program is redundant: could it not distinguish nouns from all the other parts of speech without the first line? In testing, we found that it was more error prone to place the major discrimination element entirely on the shoulders of one command, and that by first eliminating some parts of speech it could more accurately identify the nouns. On its own, SpaCy is only 90% accurate in labelling the part of speech of each word. We reasoned that it was more important to avoid spurious keywords than to ensure that all keywords were represented, since the goal of this index is to help a human researcher find useful information. Other use cases might choose a different priority, and in fact our three forms of search (global search, linear index, and MNI) offer complementary paths through the site. No one tool exhausts the paths through the site entirely.
The rest of the program manages the connections between information in such a way as to generate a table containing hundreds of rows and many keywords per row.
Some errors are visible in these few lines: “Alleged” should not have been included, and “Substratum” and “substratum” are duplicates that were not properly united, apparently because the language model incorrectly labeled the capitalized version “Substratum” as a proper name. Also, the French language words in Scheil’s text confuse the system because it cannot distinguish French words from the English in the surrounding text, which means the French text is incorrectly labeled. Still, it is an acceptable rendering of the keywords of each bibliographical entry, not messier or more redundant than the keyword list generated by our research team.
Back to top: MNI: Detailed Explanation
Generating the Multinodal Index
Calculating the strength of connection between each node representing a single work in the bibliography is a question of how to model the data, and is a crucial interpretative step. Many different approaches could be useful at this point. For the purposes of our MNI, we consider two nodes (or bibliography entries) to be “connected” if they share at least five keywords, and not connected if they share less than five. Similarly, the size of each node is determined by the number of keywords in it. More detailed bibliographical entries, with more keywords, are represented as larger nodes. For instance, a search for the term “spiritual” returns the following image:
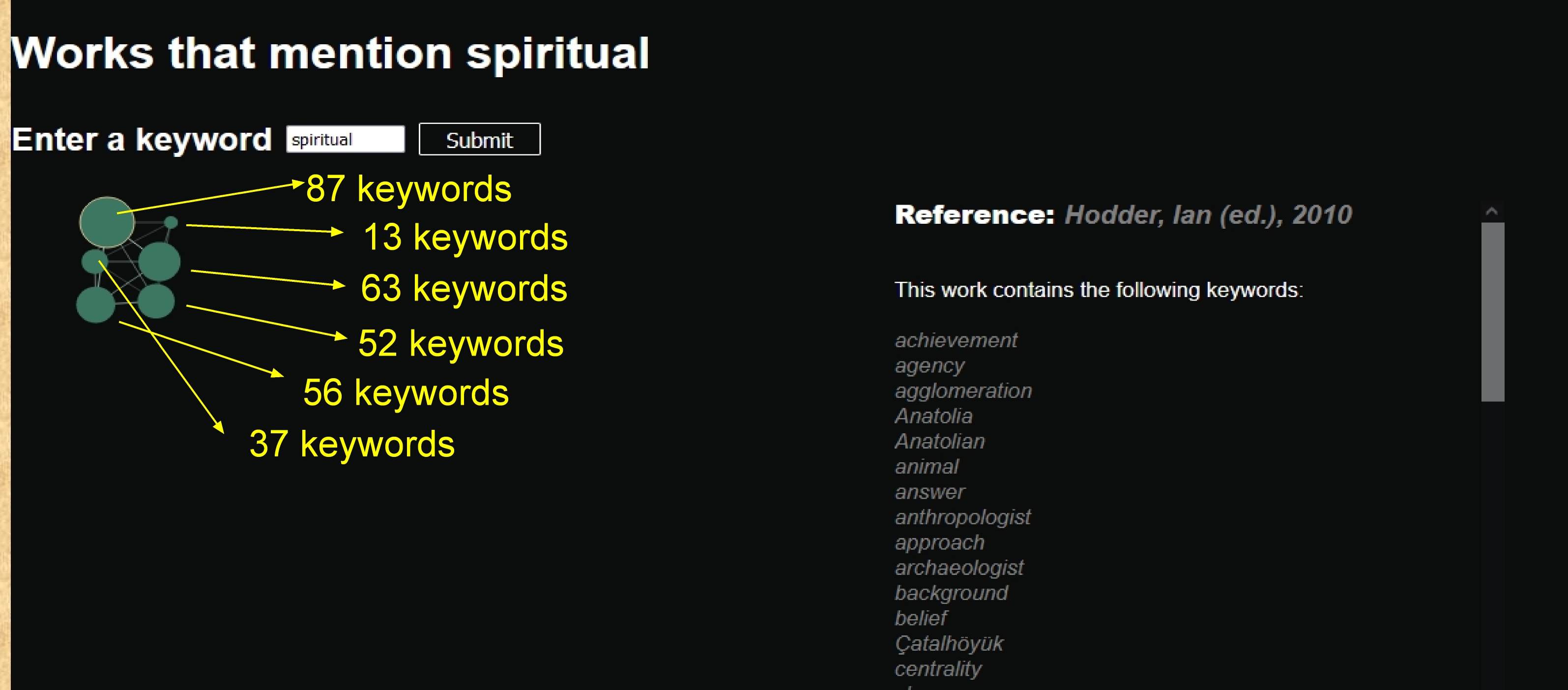
Larger nodes contain more keywords, and by clicking on them the right-hand side of the screen displays the list of keywords as well as a direct link to the bibliography entry of the work in question. Note that in this example, the search term “spiritual” (which is an adjective) in fact returns entries that contain the term “spirituality” (which is a noun), because the index was created only using nouns. It would be possible, and could be useful, to produce different indices using different parts of speech, different connection strength thresholds, and different features represented by the size and placement of the graphical elements. The decisions about which features of the data to represent by which visual feature can drastically change the interpretive possibilities. For ease of use and clarity of exposition, we have chosen features that can be interpreted as discussed above and in the quickstart; many other possibilities exist and could be usefully explored.
Once the connection strength calculation is performed, it is possible to plot the nodes and their connections as a force-directed graph. This representation offers a simple and intuitive map of the density, or lack thereof, of groups of nodes. It shows which bibliographical entries cover a similar “semantic space”, and which are isolated from the rest.
Back to top: MNI: Detailed Explanation
Graphical Representations - Force-Directed Graph
Force-directed representations are based on the physics of charged particles connected by springs. Each particle is positively charged and repels all the others; each spring pulls the two particles it connects together with a force proportional to the strength of the connection.
Thus, in our representation, each node has a “charge” that is proportional to the number of keywords it contains. Left to themselves, each particle will repel all the others and fill the space with a maximum distance between all particles. And many of the nodes are connected with “springs” that pull them together, with an attractive force in proportion to the number of keywords they share. This means that the space will be filled with clusters of related nodes, and less-related clusters or unconnected single nodes will be pushed away, where they can easily be identified.
It is important to recognize that the algorithms that display force-directed graphs make use of a randomization that starts with a random initial distribution and then “shakes” the graph to allow it to spread out to fill the space evenly. They also stop the “shaking” process after a short time, in order to find a balance between optimizing the graphical layout, and doing so in a time the user feels is not too long. These facts imply that the layout on the screen is not identical every time the representation is calculated. In force-directed representations, the orientation of the layout is not significant, while the network structure itself is invariant and significant.
A simple force-directed graph is below:
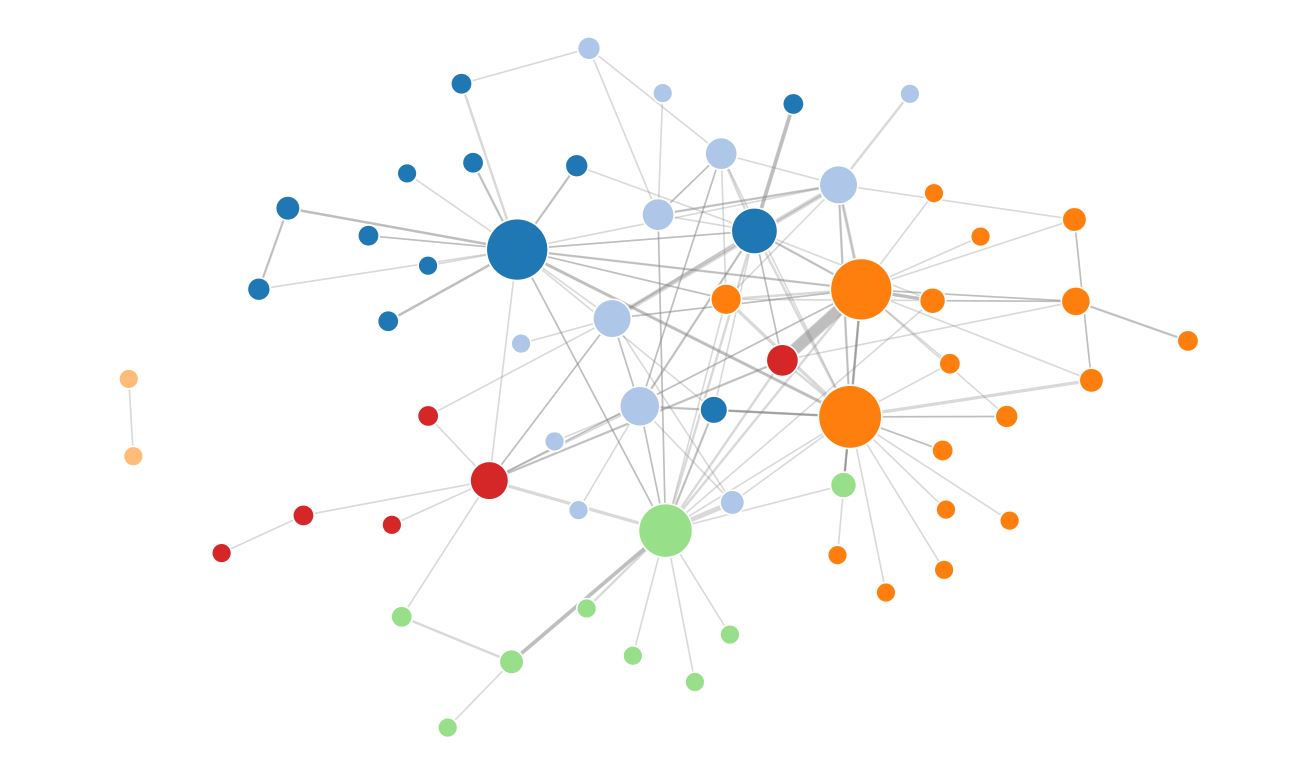
From this representation, one can immediately see that the two light orange nodes on the left are unconnected to the rest of the graph. In the MNI, unconnected nodes in the keyword search represent works that do contain the search term, but do not share more than five keywords with any other work that contains that search term. It might be useful to understand what they are, and why they are eccentric with respect to the rest. Similarly, one can see that a small number of large nodes act as “gatekeepers” holding the network together, in a sense controlling “traffic” between less well-connected nodes. In our representation, this fact might mean that they are among the more important works in the bibliography, since they have been described at greater length.
The force-directed graph representation allows an intuitive way to navigate the bibliography that contains more information than a simple keyword search could provide. In a keyword search, or in the linear index, works are not distinguishable on the basis of the “semantic space” they cover. All works that contain a given keyword are on the same level, so to speak. By using a force-directed graph representation, it is possible to give the user a bit more information about which works are most relevant, important, and well-connected to the rest of the present corpus.
It is important to again remember that these representations are based only on the bibliographical material present on this site. Therefore, they do not necessarily represent the actual content of the author’s body of work, but only the subset present on this site, filtered through the lens of the scholars who summarized the work(s) in the bibliography.
Back to top: MNI: Detailed Explanation
Graphical Representations - UMAP Projection
The projection of the entire “keyword space” onto a two-dimensional surface is a complex problem. It can be likened to a two-dimensional shadow of a higher-dimensional structure, and like the shadow of a sculpture, it contains something of the original structure, while also being an impoverishment of it.
Our visualization produces a map of the keywords present in the bibliography, and assigns them a location on a two-dimensional surface in such a way as to retain some of the high-dimensional structure of the keywords. In our case, the spatial closeness between keywords can be interpreted as a measure of their semantic similarity. Representing high-dimensional data on a two-dimensional screen is the object of intense research in data science. One of the first methods was called PCA. Another popular method, known as t-SNE, was developed by van der Maaten and Hinton in 2008. See distill.pub for an introduction to the method, with interactive visualizations that help see how powerful the procedure is, and how easy it is to misinterpret its results. Our multinodal index uses a UMAP projection of the keywords, which is a recently developed procedure (2018) based on t-SNE. An introduction, with interactive visualizations, written by Andy Coenen and Adam Pearce can be found at pair-code.github.io. The examples on that page offer an easy way to intuit the nuances of the problem of projecting high-dimensional semantic structure of the list of keywords to two or three dimensions. While our UMAP projection currently adds only a little to the reader’s ability to intuit the distribution of topics across the website, it is likely that further research will augment our ability to interpret the meaning of the projection space and increase the usefulness of this “map” of our website. Several recent studies have applied this technique to map domains of textual information, and it seems to be a promising approach.
See here for an analysis of this approach applied to biomedical research. To our knowledge, we are the first to apply it to ancient history.
Back to top: MNI: Detailed Explanation